 Session 707 of SAA2007 in Chicago discussed many aspects of the project that created Publishers’ Bindings Online (PBO). The full title of this session was The Anatomy of a Collaborative Digital Project and Lessons Learned in the Realms of Access, Outreach, and Creative Success: A Multi-Disciplinary Look at Publishers’ Bindings Online, 1815-1930: The Art of Books. The presenters have kindly posted the full slide deck from their panel online. In this post I attempt to capture the main points of the presentation and Q&A discussion of PBO.
Session 707 of SAA2007 in Chicago discussed many aspects of the project that created Publishers’ Bindings Online (PBO). The full title of this session was The Anatomy of a Collaborative Digital Project and Lessons Learned in the Realms of Access, Outreach, and Creative Success: A Multi-Disciplinary Look at Publishers’ Bindings Online, 1815-1930: The Art of Books. The presenters have kindly posted the full slide deck from their panel online. In this post I attempt to capture the main points of the presentation and Q&A discussion of PBO.
Who Spoke?
Jessica Lacher-Feldman (session chair) – University of Alabama, PBO project manager
Amy Rudersdorf – now at North Carolina State University, Digital production coordinator, NCSU special Collections, but was at University of Wisconsin, Madison during PBO project
Kristy Dixon – University of Alabama , PBO staff
PBO Project Overview
PBO was made possible by a 3 year Institute of Museum and Library Services (IMLS) grant. Originally awarded in 2003, the grant was extended once (and I think they mentioned additional funding being applied for). The primary grant funded the digitization of 10,000 images from up to 5000 book bindings. Ultimately 10,570 images were added to PBO and made searchable by metadata. The bindings selected included books from 1815-1930, primarily US titles and mostly in English.
Their guiding vision was of “giving something to the world that is both needed and useful” (and really beautiful). And they succeeded! PBO is a lot more than 10,000+ digitized book bindings. The project strived to make the information available in many different ways, including via:
- a web-based database
- online exhibits & galleries,
- vodcasts and podcasts
- web-based tutorials
- virtual and real exhibits
- presentations & class lectures
- opportunities to adapt the project to other disciplines – history, book arts, librarianship, literature.. K-12 and more
Technology and Processes
The division of labor for PBO was split between the University of Alabama and the University of Wisconsin, Madison.
Many extensions to the OCLC SiteSearch based database were made by the UWDCC (UW Digital Collections Center) digital production center at the University of Wisconsin, Madison .
They went through an overview of the participants and staff – who did what.. what skills were needed and what was brought by the two institutions to the collaboration. They acknowledged their fabulous advisory group including Sue Allen – “the expert on publisher’s bindings”. Individuals from outside their teams contribute based on their special interest and knowledge about a specific individual (this contribution is still ongoing).
Working in collaboration forced them to wrestle with many challenges including:
- staff in two locations – most of whom had never met
- “long distance relationships are hard”
- they had to work hard to ensure that all were ‘equally-valued participants’
- standards – you need ground rules from the outset
Collaboration & Description
“Every pair of eyes are different”. PBO tapped into the resource of the ‘young fertile minds’ to power the project out of the local MLS programs at both institutions. Even with a detailed description form – there was confusion over subject headings and overlap – especially when those selecting subject headings were grad students who might not know the official terms for things. For example, the list of terms might include Ouroboros – but the students might not know this it is the term for a snake eating it’s own tail.
Ultimately they had to do quality control at a single location. They spent a LOT of time on this.
Their top tips for cultivating continuity for virtual project teams:
- write into your grants money for travel (they stressed that your grant includes funds to support people meeting each other)
- continuous communication is critical
- ‘shared working group website’ available online
- email, conference calls and instant messaging (IM) for communication
- regular reporting to each other
- being project manager means that you have to be on top of everything – you need to be the glue
- focus on the deliverables – use planning tools and timelines
They discovered that IM was key to developing trust between the two institutions.
Metadata – the core of the project
The key to their metadata approach was to consider a book less as a ‘bibliographic object’ and more as an ‘art object’.
They called books in PBO ‘objects’ but still kept the bibliographic metadata. They used Dublin Core by pulling the MARC data into the Dublin Core structure. As part of this they took all the subjects from the bibliographic info and moved it to the Dublin Core description and labeled it ‘book topic’. Then they used the ‘Subjects’ portion of the Dublin Core record to describe the binding and talk about what the images are OF. This is where the subject terms from the controlled vocabulary were added.
These are the steps of their metadata workflow process:
- selection from collections of note – faculty, consultants and library staff did this step
- description – used a paper form, described the books on paper and joined that description to what was in the MARC record – done by the grad students and library staff
- metadata entry – entry of data through an online form – done by students (overseen by library staff) actually ended up being cheaper to manually enter the MARC data (rather than automated extraction)
- quality control – content, grammar, spelling – done by library staff (took a lot more time than anyone expected)
- no live update between their working Filemaker Pro database and the final SiteSearch database
- record ownership – indicated in the identifier field (with a special code in the identifier) AND in the Submitter field
A lot of description went into this project.
They needed to develop a controlled vocabulary for the project. To do this they first worked with content specialists to develop a list. They used Library of Congress Subject Headings (LCSH) terms where they could, as well as Getty Art and Architecture Thesaurus. Then they added some local terms. The controlled vocabulary list evolved with the project and is the foundation of all teaching, search and more.
The speaker showed an example of the controlled vocabulary – the terms really are a window into the past. Users can browse the controlled vocabulary through the front end.
On the description paper form they had a list of ‘binding themes’ for those doing the description to pick from. A lot of work was done to get the huge list of themes onto a single page. Ultimately they had to provide some fill in the blank extension fields. For example, rather than believing they had listed every useful trade or profession, there was a section on the list labeled: Profession/Trade – _______________ with the expectation that those describing a binding might need to fill in the blank.
Digitization and The Database
Generally two scans were taken from each book, but sometimes as many as five. What did they scan? Front cover, spine, back cover and end papers.
There were two different image reformatting standards at the two institutions – 300 DPI vs 600 DPI. Both used a black background when scanning. All books were presented in as in condition – some have front/back covers missing. After the scanning they began with master TIFs and then transformed them to JPGs in three sizes in 72 DPI.
The presentation showed screen shots of:
- simple search
- brief view record in search results — which includes subjects
- full record view – including display of all images associated with the book object record
- gallery view – thumbnail, title and indication if there are one or more images related to the title
- guided search (advanced search)
- clickable subject headings
All the images in PBO are freely available for download.
With an eye to digital preservation, all the original uncompressed TIF images are archived in triplicate to digital archive tape and stored in three different locations. The metadata is stored with images in both text and SGML format (which is what SiteSearch works with). The full process documents are available on the project site.
Future Growth
The PBO team is talking to Louisiana State University (LSU) to figure out how PBO can grow. LSU would need to work and live with the way PBO works and learn their processes. They are talking to other institutions – if you are interested in adding content to PBO, please contact them.
The Richard Minsky Collection has been purchased and is being added to the project. This is a rich collection that was gathered to create a catalog. PBO has the catalog and all of Minsky’s research that goes with the collection. The goal is to feed as much of this rich data into PBO as possible. They are working with individual scholars and collectors to find other avenues for growth.
Value Added Components
One of the focuses of PBO has been to look beyond the digital images themselves to creating value added components for their user community.
A tutorial for users is provided, including information about how to email a record. A comprehensive bibliography has been created and is used by scholars. The page prompts users to submit feedback so the bibliography is a live document.
Over 30 galleries have been created – organizing access to essays and additional info by topic. Types of galleries include:
Links to trusted information outside of PBO’s site are shown whenever possible. For example – links to the full text of books are provided via Project Gutenberg. Throughout the site’s text link to sources such as the Library of Congress, .gov sites, PBS and so forth can be found.
Canned searches are provided to make it easy for users to explore content. An example of this is the Silver & Gold: The Art of Metal Stamping search that will find every binding with either silver or gold stamping. This is in contrast with making users figure out the right syntax to submit the search criteria themselves.
The Teaching Tools portion of the site provides sample lesson plans on all sorts of topics. They worked with some high school history teachers via focus groups and got feedback about what they needed and wanted. The Industrial Revolution lesson plan was created based on that feedback.
The research tools that were created as a result of the PBO project and are made available online are:
Signed or Designer bindings is a new resource to which scholars continue to contribute new information.
Through collaboration with teaching faculty they developed the presentation such as Indians, the Frontier, and the West in American Bookbindings. This presentation will eventually be podcast on the PBO site. It talks about how these books inspired people to move west and inspired kids to read.
Another podcast is on the way addressing the representation of Uncle Tom’s Cabin. It will discuss how the book was it marketed to different groups – Yiddish, German… etc. There already exists a gallery and essay on Uncle Tom’s Cabin .
Conclusions
The team has been very pleased by the tangible scholarly impact of PBO. They have seen extensive collaboration with the university community, new research, and promotion of the use of special collections materials in the classroom using digital resources. They point to PBO as showing a path to preserve these increasingly fragile books by moving out of the general stacks and into special collections – with a result of increased access to the book and decreased handling.
The presenters avowed that PBO could never have been created by their team alone – working with consultants and advisers was the key to their success. They needed input from experts and others to help PBO grow and keep it sustainable. This interaction makes the project strong – it has it’s own legs and won’t cease to exist when the money disappears.
Publicity and outreach got attention on the PBO project from the very beginning. They made documenting their experiences and making recommendations about how to market digital projects part of the original plan in their grant proposals. These documents were part of their deliverables. They even published a white paper about PBO and outreach.
PBO uses Google Analytics so they can see where their users are coming from. Also it makes cool talking points for your reports and fun things to tell the Dean!
I think the best conclusion to my summary of the presentation portion of this session is the list of points on the final slide titled “Beyond the grant: Room to Grow”:
- Potential future contribution from other repositories in the US and abroad…
- Potential future collaboration with teaching faculty at UA and beyond
- With additional collections, the database and the project will only grow stronger
- Potential as a web portal, clearing house, or consortium
- Additional potential funding opportunities, scholarship, and ways to highlight collections, resources, knowledge, and abilities
Questions and Answers
Keep in mind throughout this section that I am summarizing and paraphrasing the questions and their answers. Please do not take any statements as full and complete quotes. In cases where I missed too much of the question or answer I generally skipped including it in the list below. If you are anxious to know exactly what was said, you would need to buy and listen to the conference recordings for this session.
Question: Who maintains the website and who makes decisions about how things are going to get updated?
Answer: UA maintains the static web pages and UW maintains the database. The project manager has been in charge.. made prototypes of new design and sent it around for feedback. They have standards for colors in their handbooks.
Question: If the grant funding dried up right now would the project be sustainable?
Answer: There is support from the institutions… for example, it is just one project of many at UW.
Question: How did you get such good scans of the book spines?
Answer : At UW they used blocks or boxes to prop up the books and laid black foam core on top on flatbed scanners. At UA – they used black paper covered blocks in combination with overhead scanners.
Question: How did you get the full cover scans?
Answer: They very carefully lay the cover flat – so the pages sticking are sticking up.
Question: Who customized SiteSearch – OCLC or UW?
Answer: UW did the work – they had one and a half dedicated IT staff to do the customizations.
Question : Have you had to negotiate copyright issues for bindings from the late end of the time range of the project
Answer: No.
Question : Are you aware of others doing similar projects? Have you been approached and or are looking for others who want to contribute?
Answer: Yes. Right now they are working with LSU and are not actively seeking out new participants. There are plans to grow the project eventually.
Question: Did you think about the fact that you were creating your own online publication?
Answer: They didn’t realize it ahead of time – they didn’t realize how powerful the database was going to be to fuel their ability to build further on the work.
Question: Can you search for ‘young people’s covers’ – is there metadata for what age groups might enjoy specific books?
Answer: It depends on if it was part of the descriptive information, but you can search on ‘boys’ or ‘girls’ or ‘juvenile’ and gain useful results.
Question: Can you talk about the work behind the MARC to Dublin Core migration?
Answer: In some ways it was easier than they thought it would be – so many of the fields transfer directly from MARC to Dublin Core.. it was the revelation about the book as art object that made them realize the work they needed to do. Building the controlled vocabularies was where the heavy lifting occurred. It involved going through giant spread sheets with subject terms in alphabetical order looking for typos and working toward consistency (ie, use plurals). The spreadsheet didn’t show how many items used each term – it was hard to know how many changes would be needed.
Question: Do you get hits from the standard online catalog into PBO?
Answer: This is not happening now. They would love to build a better connection between the OPAC and PBO in both institutions.
Question: How did you make decisions when there were disagreements?
Answer: “I don’t remember any more.. it was all so beautiful…” <laughter > . There were no big issues about standards. There were more issues about the grant and things like how many images or books they were supposed to scan. In some cases it was easy because they were in charge of very different project areas – each team had “their own little fiefdom”.
Question: Do you think you might sell images to generate revenue?
Answer: They have considered it. The have made a calendar and a poster, but gave them away. They also have used images for making holiday cards. They don’t see selling images as a main goal right now.
Question: Have you considered pursuing online collaborative methods for work with the scholars and collectors?
Answer: No, but they think that would be useful to explore.
My Thoughts
I loved the energy and connection displayed by the presenters. It was fun to see a team of people who clearly were so proud of their work and pleased by its reception. I was personally intrigued by the highlighted challenge of coming up with (and painstakingly validating) their controlled vocabulary for subjects. I firmly believe that the topic of subject terms and their standardization across repositories will only grow in importance. For those interested in some of what is being done on this front – take a look at both the UK based High Level Thesaurus (HILT) and the Simple Knowledge Organisation Systems Core (SKOS) project. I suspect many will be intrigued by the SKOS use case titled An integrated view to medieval illuminated manuscripts.
Even given the mammoth effort required to create a shared controlled vocabulary, it is clear that the benefits they have reaped from this effort are still being discovered. The speakers mentioned on multiple occasions how pleased (and surprised) they were to realize how powerful their database of metadata has proven to be. All the amazing value added features build on this ‘heavy lifting’.
While it will be rare for such item level attention to be given to most archival documents, PBO sets the bar high for what can be done via collaboration across institutions. Their dedication to sharing their lessons learned is a fine example of what all big projects who are forging new frontiers could be doing. Finally – it is the weight of all the value added elements (galleries, tutorials, lesson plans.. and the list goes on) that have raised what could have been just a set of classified images in a database to being an active community with a growing draw for many types of users from around the world.
As is the case with all my session summaries from SAA2007, please accept my apologies in advance for any cases in which I misquote, overly simplify or miss points altogether in the post above. These sessions move fast and my main goal is to capture the core of the ideas presented and exchanged. Feel free to contact me about corrections to my summary either via comments on this post or via my contact form.
 My trip to the 2008 Information Architecture Summit (IA Summit) down in Miami has me thinking a lot about helping people find information. In this post I am going to examine clustering data.
My trip to the 2008 Information Architecture Summit (IA Summit) down in Miami has me thinking a lot about helping people find information. In this post I am going to examine clustering data. Del.icio.us, a web service for storing and tagging your bookmarks online, supports what they call ‘related tags’ and ‘tag bundles’. If you view the page for the tag ‘archives’ – you will see to the far right a list of related tags like those shown in the image here. What is interesting is that if I look at my own personal tag page for archives I see a much longer list of related tags (big surprise that I have a lot of links tagged archives!) and I am given the option of selecting additional tags to filter my list of links via a combination of tags.
Del.icio.us, a web service for storing and tagging your bookmarks online, supports what they call ‘related tags’ and ‘tag bundles’. If you view the page for the tag ‘archives’ – you will see to the far right a list of related tags like those shown in the image here. What is interesting is that if I look at my own personal tag page for archives I see a much longer list of related tags (big surprise that I have a lot of links tagged archives!) and I am given the option of selecting additional tags to filter my list of links via a combination of tags.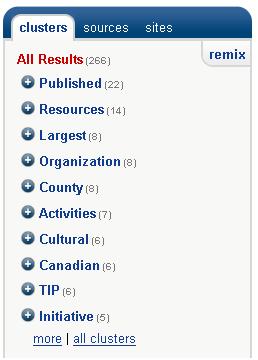 An example of what this might look like for search results can be seen via the search engine Clusty.com from the folks over at Vivisimo. For example – try a search on the term archives. This is one of those search terms for which general web searching is usually just infuriating. Clusty starts us with the same top 2 results as a search for archives on Google does, but it also gives us a list of clusters on the left sidebar. You can click on any of those clusters to filter the search results.
An example of what this might look like for search results can be seen via the search engine Clusty.com from the folks over at Vivisimo. For example – try a search on the term archives. This is one of those search terms for which general web searching is usually just infuriating. Clusty starts us with the same top 2 results as a search for archives on Google does, but it also gives us a list of clusters on the left sidebar. You can click on any of those clusters to filter the search results.
")

 Diane Kaplan, of
Diane Kaplan, of {kind=link}
{kind=link}